【Python】pandasで日時をグループ集計する方法
概要
pythonでデータを扱うのに便利なライブラリとしてはpandasがあります。
このpandasを用いてグループで集計する方法についてメモしておきます。
テストデータ
以下のようなテスト用の時系列データフレームを用意します。
import pandas as pd
from pandas import Series
datetime = pd.date_range(start='2021-12-31',end='2022-01-02', freq='30s')
df = pd.DataFrame(range(len(datetime)), index=date, columns = ['val'])df.head()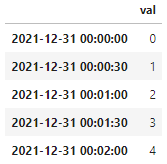
df.tail()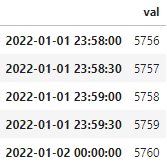
方法1 : resampleを使う
日時のグルーピングについてはpandasのresampleメソッドを使用することで集計することができます。resampleはダウンサンプリングするためのメソッドですが、集計用途にも使用できます。
resample関数を使用するためには以下の二つの注意が必要です。
- グルーピング対象項目はdatetime型にしてindexとしておく
df['datetime'] = pd.to_datetime(df['datetime'])
df.set_index('datetime', inplace=True)あとはresampleの引数にグルーピングしたい単位を入力すれば簡単に集計されます。
df.resample('Y').sum()
df.resample('M').sum()
方法2 : Grouperを使う
pandasのGrouperを使用する方法です。こちらの場合はダウンサンプリングではなく、単にある項目でグループ化できる機能であるため、集計用途であればこちらの方が汎用性が高いと思います。
基本的な使い方としてはこのような形です。
df.groupby(pd.Grouper(freq="Y")).count()
df.groupby(pd.Grouper(freq="M")).count()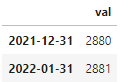
このようにresampleと同じような形で使用することができます。
また、Grouperの場合はindex以外の列を直接指定してグループ化することもできます。
一旦グループ化したいdatetime列をindexから外します。
df_notindex = df.reset_index().rename(columns={'index':'datetime'})
df_notindex.head()Grouperの引数keyとしてdatetime列を渡すことで集計できます。
df_notindex.groupby(pd.Grouper(key="datetime",freq="Y")).count()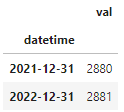
また、複数のカラムでグループしたい場合はgroupby自体の引数の中にリストで渡すことで実現できますので、汎用性が高いです。
pandas.groupby([pd.Grouper(key="datetime",freq="Y"),'column1','column2']).count()まとめ
- pandasで日時でグループ集計したい場合にはresampleやgroupby,Grouperが使用できる。
- groupbyを使用した方が汎用性はありそう