【Python】pandasのgroupbyで最大・最小となる値の他の列の値を抽出する方法
概要
pythonのpandasでgroupbyメソッドを使用することで、列のあるグループにおける最大値や最小値を取得することができます。
例えば以下のようなデータの場合の例で考えます。
import pandas as pd
df = pd.DataFrame([['10:00:00','A',10],['10:00:01','A',11],['10:00:02','A',10],['10:00:03','B',5],['10:00:04','B',5],['10:00:05','B',4]])
df.columns = ['time','category','value']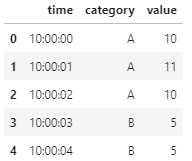
上記のデータにおいてA,Bにおける最大値を取り出したいとします。
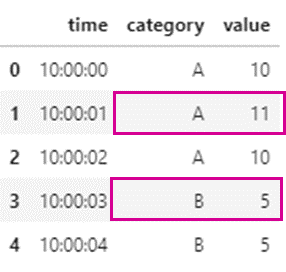
その場合、コードでcategoryがA、Bのそれぞれにおける最大値を簡単に取得することができます。
df_value_max = df[['category','value']].groupby('category').max()
ただし、時には、カテゴリA、Bの値と一緒に、最大になるときのほかの列の値も取得したいこともあると思います。
上記の例だと、time 列においてそれぞれAが最大となる”10:00:01″とBが最大になる”10:00:03″を取得したいような場合です。
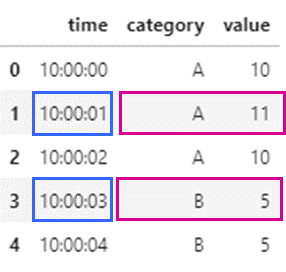
今回はこれらを取得する方法について考えてみました。
結果のコード
結果から言うと、以下のコードで実現することができました。データを読み込むところからの全体のコードです。
#ここはデータの読み込み部
import pandas as pd
df = pd.DataFrame([['10:00:00','A',10],['10:00:01','A',11],['10:00:02','A',10],['10:00:03','B',5],['10:00:04','B',5],['10:00:05','B',4]])
df.columns = ['time','category','value']
#データ抽出の部分
df = df.reset_index()
df_idx_max = df[['category','value']].groupby('category').idxmax()
df_idx_max.columns = ['max_idx']
df_mrg = pd.merge(df, df_idx_max, left_on='index', right_on='max_idx')
df_mrg.head()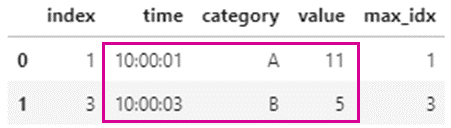
2021/12/24 追記
コメントで教えていただいた以下のコードの方が断然シンプルに実現できましたので追記させていただきます。
#データ抽出の部分
df = df.reset_index()
df.loc[df.groupby('category')['value'].idxmax()]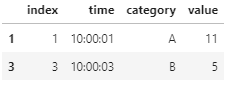
説明
順番にコードの説明をしていきます。
まず、最初にデータを読み込み適当なカラム名を付けます。
import pandas as pd
df = pd.DataFrame([['10:00:00','A',10],['10:00:01','A',11],['10:00:02','A',10],['10:00:03','B',5],['10:00:04','B',5],['10:00:05','B',4]])
df.columns = ['time','category','value']次に、reset_index()メソッドを使用してindexを列化しておきます。これは最後にmergeメソッドを使用するつもりなのですが、その際に結合する列をわかりやすくするためです。
df = df.reset_index()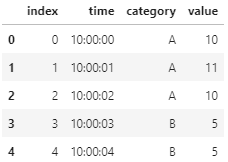
次が結構重要な部分になります。idxmaxメソッドというものを使用し、categoryにおいて、valueが最大となる際のindexを取得します。なお、最大の値となる行が重複する場合には最初の行番号が取り出されるようです。
また、結果の列名にわかりやすい名前を振っておきました。
df_idx_max = df[['category','value']].groupby('category').idxmax()
df_idx_max.columns = ['max_idx']
このidxmaxメソッドは非常に強力です。というのも、idxmaxを使用するとわざわざmaxメソッドを使用する必要がなくなるためです。
なぜなら、dfを左側としてindexとmax_idxをキーに内部結合することで以下のようになります。
df_mrg = pd.merge(df, df_idx_max, left_on='index', right_on='max_idx')
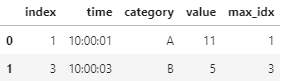
内部結合により、category列の各値におけるvalueが最大になる行のみを取り出すことができました。
これにより、当初目的としていたtimeの値も抽出することができました。
なお、idxminを使用することで最小の場合のほかの列の値も取得することができます。
まとめ
groupbyのidxmaxメソッドとmergeメソッドを併用することで、ある列の各値において値が最大となる場合のそのほかの列の値を取り出すことができることがわかりました。

#データ抽出の部分
df.loc[df.groupby(‘category’)[‘value’].idxmax()]
とするのがよいと思います。
yakn9さん
断然シンプルになりました。ありがとうございます。