【TensorFlow】preprocessing.timeseries_dataset_from_arrayの使い方
概要
kerasの時系列予測のチュートリアル(Timeseries forecasting for weather prediction (keras.io))を見ていたところ学習用データセットを作成する際にtf.keras.utils.timeseries_dataset_from_arrayというメソッドが使われていました。
引数がいろいろあるので最初に使い方に少し悩んでしまったのですが、使い方を覚えてしまえば非常に便利なメソッドだったので紹介します。
使いどころ
時系列データなどにおいて学習用のデータセットを作成する際に有用です。
ある時系列データの中から、サンプリング周期、シーケンス長さ、シーケンスストライドを指定することで自動的に学習用のバッチデータを生成してくれます。
TensorFlowのサイトにメソッドの説明や例が載っていますので正確な挙動はこちらを参考にするのが良いです。
tf.keras.utils.timeseries_dataset_from_array | TensorFlow Core v2.8.0
検証環境
python 3.8.10
keras 2.7.0
実例
関数の挙動について実例を踏まえて紹介していきます。
まずは、テスト用のデータを用意します。
data = [i for i in range(20)]
print(data)[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
次に、timeseries_dataset_from_arrayを実際に使用していきます。
import tensorflow as tf
dataset = tf.keras.preprocessing.timeseries_dataset_from_array(
data,
targets=data[10:],
sequence_length=5,
sequence_stride=3,
sampling_rate=2,
shuffle=False,
) 私なりに解釈した結果、各パラメータは以下のような意味合いだと思いました。
data : 学習用データセットに使用する入力データ。
targets : 学習する際のターゲットデータ。例えば、時系列予測などを行う場合は予測値の正解データなど。
sequence_length : 各シーケンス(ウィンドウ)における要素数。
sequence_stride : シーケンス(ウィンドウ)の間隔
これだけではいまいちわかりにくいため、作成されたdatasetの中身を見ていきます。
for batch in dataset:
print(batch)(<tf.Tensor: shape=(4, 5), dtype=int32, numpy=
array([[ 0, 2, 4, 6, 8],
[ 3, 5, 7, 9, 11],
[ 6, 8, 10, 12, 14],
[ 9, 11, 13, 15, 17]])>, <tf.Tensor: shape=(4,), dtype=int32, numpy=array([10, 13, 16, 19])>)BatchDatasetオブジェクトとして上記のような結果が得られました。
これを各パラメータと合わせて見てみると次のような感じになります。
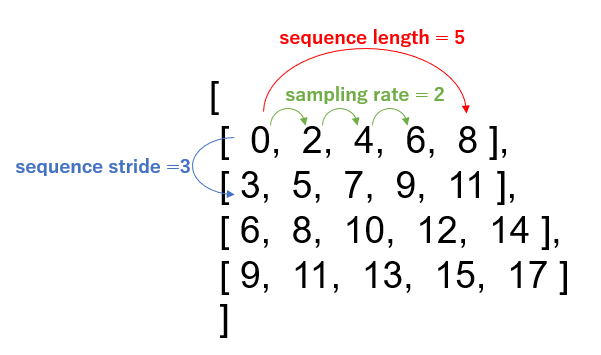
これはつまり、時系列予測の学習を行わせようとしている場合に、
[0, 2, 4, 6, 8]に対して正解が 10[3, 5, 7, 9, 10]に対して正解が 13[6, 8, 10, 12, 14]に対して正解が 17[9, 11, 13, 15, 17]に対して正解が 19として学習できるようなデータセットになっているということです。
正解ラベル側をshapeに合わせて調整してくれるところが非常に便利だと思いました。
まとめ
このように、tf.keras.utils.timeseries_dataset_from_arrayは時系列予測などのタスクを行う際に学習用データセットを作成するのに非常に効率的なメソッドです。今後深層学習タスクを試す場合などに積極的に活用していきたいと思います。