【Python】データから確率密度関数を推定する
概要
統計学で連続的な確率変数の値を扱う場合には確率密度関数を用いて確率を定義します。
今回はPythonで実データから確率密度関数を推定する方法について簡単に紹介していきます。
環境
Python 3.8.10
使用データ
Justin Kiggins氏がOpen Datasourceとして公開されているAvocado Pricesのデータを使用します。kaggleからダウンロードできます。
確率密度関数を求める手順
データの読み込み
kaggleのサイトからデータをダウンロードし、pandasのread_csvを使用して読み込みます。
import pandas as pd
df = pd.read_csv('.//datasets//avocado.csv')
df.head()
今回の例ではAveragePriceを使用していきます。
ヒストグラムを見てみる
まずはAveragePriceの分布をみてみます。matplotlibのhistを使用することで簡単にヒストグラムを表示することができます。ただし、入力がnumpy配列である必要があるためnumpyのto_numpyメソッドで事前に変換しておきます。
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
#numpy配列へ変換
data = df['AveragePrice'].to_numpy()
#ヒストグラム表示
plt.hist(data)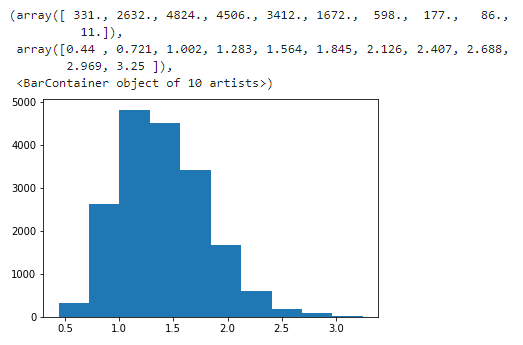
これだけでもデータの特性の概要はわかりました。今回はさらにここから確率密度関数を求めてこの日ストグラムの上に描画していきます。
カーネル密度推定
確率密度関数の推定としてKernel Densityを使用します。KernelDensityはノンパラメトリック法と呼ばれる確率密度関数推定の方法になります。
scikitlearn.neighborsのKernelDensityというものがあり、とてもシンプルに使用できるためこちらを使用します。
2.8. Density Estimation — scikit-learn 1.0.2 documentation
from sklearn.neighbors import KernelDensity
#カーネル関数はガウシアンでモデルフィット
kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(data[:,None])
#モデル入力用のX軸データ用意
x = np.linspace(0,3.5, 2000)[:,None]
#KernelDensityモデルで確率密度計算
dens = kde.score_samples(x)
#描画用fig準備
fig = plt.figure()
ax1 = fig.add_subplot(111)
#第一軸にヒストグラム描画
ax1.hist(data)
#第二軸に確率密度関数による推定値を描画
ax2 = ax1.twinx()
ax2.plot(x, np.exp(dens),color='orange')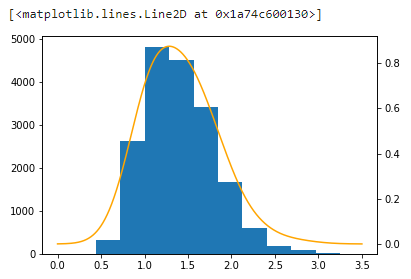
seabornを使う方法
seabornにはkdeplotというメソッドがあり、単に確率密度関数を描画するだけであればこちらを使用することで一瞬で描画できます。
seaborn.kdeplot — seaborn 0.11.2 documentation (pydata.org)
import seaborn as sns
sns.kdeplot(data=data)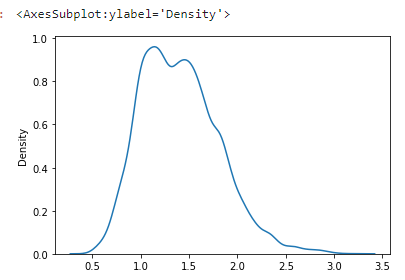
まとめ
pythonを使うことでデータから確率密度関数を求めることが簡単にできます。ヒストグラムと重ねて確認などもできるので妥当性がわかりやすくていいです。