【Python】DataFrameの一列をきれいにリストへ変換する
概要
pythonでデータベースからデータを取得するときに非常に便利なライブラリとしてpandasがあります。read_sqlメソッドを使うとことでselect文を使用してデータベースからDataFrame型でデータを取得できます。
ただ、データベースのテーブルのうちの一列だけリスト型で取得したいときに少し躓いたので、対処方法についてメモします。
データベースから一列取得する例
例えば、データベース側(PostgreSQLとします)に以下のようなテーブルがあったとします。
| a | b | c |
| 1 | 10 | 100 |
| 2 | 20 | 200 |
| 3 | 30 | 300 |
| 4 | 40 | 400 |
この表からa列だけをpandasで取り出してみます。
import pandas as pd
import psycopg2
connection = psycopg2.connect(host='host', dbname='database', user='username', password='password')
df = pd.read_sql("SELECT a FROM test_table", connection)
df.head()結果
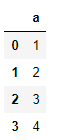
このa列をリストにしたいなぁ、思ったとき、直感的にはイメージするのは[1,2,3,4]みたいなリストだと思います。
では、実際にこれをリスト化してみます。
df.values.tolist()
結果
[[1], [2], [3], [4]]二重リストで出てきてイメージと違う・・・
当たり前ですが、いくらselect文で一列だけ取り出してもDataFrameはDataFrameなので、values.tolist()でリスト化しても二重になってしまいます。今回はこれを一重リストにします。
一重リストにする
itertoolsを使うことで、以下のコードで実現できます。
import itertools
a = df.values.tolist()
list(itertools.chain.from_iterable(a))
結果
[1, 2, 3, 4]非常に便利なので、今後も使用する機会が多くなりそうです。
Pythonを一から学ぶのにおすすめの本はコチラ