【Python】pandas でnanデータを判定する方法
概要
pandasで読み込んだデータで、NaNを判定したい場合に、条件式をどう書いたらいいか迷うときがあるのでまとめました。
データ
以下を使います。(ヘッダなし)
30,test1
,test2
50,以下で読み込みます。後でnumpyも検証するのでimportしておきます。
import pandas as pd
import numpy as np
df = pd.read_csv('nantest.csv',header = None)
df.head()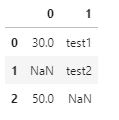
NaNの判定パターン
DataFrameで判定する場合
pandasのisna()メソッドで判定できます。
df.isna()
また、isnull()メソッドでも判定できます。
df.isnull()
Seriesで判定する場合
isna()メソッドで判定できます。
df[0].isna()
df[1].isna()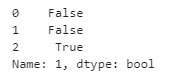
また、isnull()メソッドでも判定できます。
df[0].isnull()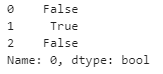
df[1].isnull()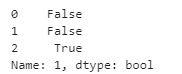
要素で判定する場合
要素で判定する場合はpandasのメソッドは使えませんので、それぞれのデータ型に合わせて判定する必要があります。
NGな例(要素にpandasメソッドのisna()を使用した場合)
このようにエラーがでます。
df[0][1].isna()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-52-0056ce2b22fa> in <module>
----> 1 df[0][1].isna()
AttributeError: 'numpy.float64' object has no attribute 'isna'OKな例
np.isnan(df[0][1])
> True
np.isnan(df[1][2])
>True引っかかりやすい例
numpy.float64のデータ型の場合は”is np.nan”では判定できない
pandasでcsvを読み取った際に要素のデータ型が自動的に決まりますが、numpy.float64として取り込まれたデータには”is np.nan”では上手く判定できません。
type(df[0][1])
> numpy.float64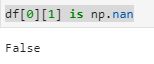
一方でfloat型で認識された場合は”is np.nan”で判定できます。
type(df[1][2])
> float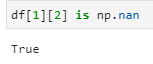
まとめ
DataFrame、Seriesの単位でnanを判定する場合はpandasメソッドの”.isnan()”か”.isnull()”を使用するのが良いです。ただし、for文などで行単位でイテレーションし、要素に対してnanを判定する場合はデータ型を意識して判定式を記述するように注意が必要です。